To those who wish to learn about machine learning and AI, there are several great resources on the web. Among them is a MOOC (Massive Open Online Course) provided by FastAI which aims to get learners straight into deep learning by building serious applications straight out the box. In the first lesson, you build an image classifier with a GPU machine on the cloud and the FastAI python package. To those wishing to better understand what deep learning is about and who don’t want to invest loads of time learning too much theory behind it, I would strongly recommend FastAI.

If you go through the first lesson of the FastAI MOOC, you’ll find that building a multi-class image classifier which can correctly identify the correct breed of cat is surprisingly easy. And this can be replicated for any other task similar to this, for instance determining whether your image contains a hotdog or not. I thought that it would be interesting to use this method to determine the correct tennis player from a set of images of top 10 tennis players.
Extracting the data
So first things first, we need data. I found that using the command line python program googleimagesdownload is an excellent way to download tons of images from Google. Here is the code that I used to download 200 images for each tennis player:
#!/bin/bash
VAR1="Novak_Djokovic"
VAR2="Rafael_Nadal"
VAR3="Alexander_Zverev"
VAR4="Roger_Federer"
VAR5="Juan_Martin_del_Potro"
VAR6="Kevin_Anderson"
VAR7="Kei_Nishikori"
VAR8="Dominic_Thiem"
VAR9="John_Isner"
VAR10="Stefanos_Tsitsipas"
for tennisPlayer in $VAR1 $VAR2 $VAR3 $VAR4 $VAR5 $VAR6 $VAR7 $VAR8 $VAR9 $VAR10
do
googleimagesdownload -pr $tennisPlayer -f "jpg" -k "$tennisPlayer tennis player" -s medium -l 200 -o data/tennis -i train/$tennisPlayer -cd /usr/bin/chromedriver
rename 's/\.(.*)/.jpg/' data/tennis/train/$tennisPlayer/*
doneSome of the images that we downloaded were corrupted and couldn’t be effectively read by our machine learning algorithm. In this case, we just identify and remove those images that can’t be opened in our python environment with PIL.
for item in ["Novak_Djokovic","Rafael_Nadal","Alexander_Zverev","Roger_Federer","Juan_Martin_del_Potro","Kevin_Anderson","Kei_Nishikori","Dominic_Thiem","John_Isner", "Stefanos_Tsitsipas"]:
for image in os.listdir('/notebooks/course-v3/nbs/dl1_mine/data/tennis/train/'+item):
try:
img =PIL.Image.open('/notebooks/course-v3/nbs/dl1_mine/data/tennis/train/'+item+'/'+image)
img.format
except:
print(image)
os.remove('/notebooks/course-v3/nbs/dl1_mine/data/tennis/train/'+item+'/'+image)Training and Testing the Model
Now to the fun part! We use the downloaded image data to train our convolutional neural network (CNN) as shown below. I won’t go into detail what each line of code means because it is explained in the FastAI MOOC video. As a quick summary, all that we are doing is loading the FastAI python package, using the from_folder function of ImageDataBunch to automatically load our data and give it the correct classification label, creating a CNN with resnet34 and fitting the data to it for 8 epochs.
from fastai.vision import *
from fastai.metrics import error_rate
from pathlib import Path
bs = 64
path = Path('/notebooks/course-v3/nbs/dl1_mine/data/tennis')
tfms = get_transforms(do_flip=False)
data = ImageDataBunch.from_folder(path, ds_tfms=tfms, size=256, valid_pct=0.2)
learn = create_cnn(data, models.resnet34, metrics=error_rate)
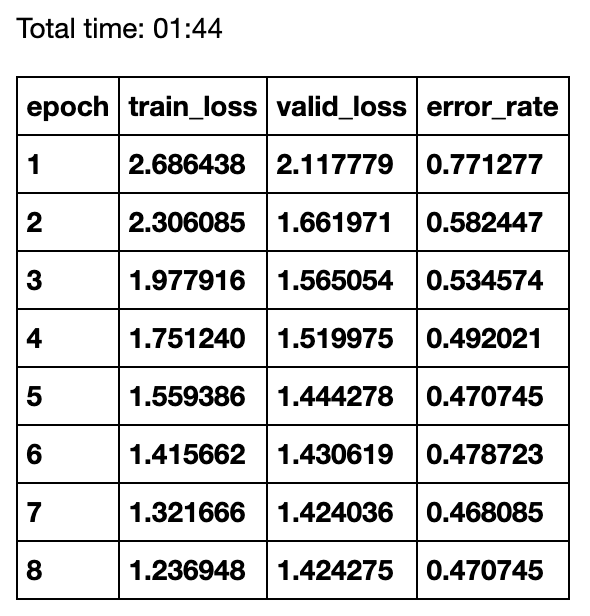
learn.fit_one_cycle(8)Running the code outputs the training loss, validation loss and the error rate for each epoch. We can see that the error rate goes down after every epoch before hitting an error rate of 47% (a 53% accuracy). There is no point in fitting the model with more epochs because we would start over-fitting on our training set.
Analysing Results
I feel kind of mixed about these results. On the one hand, I feel that the performance is impressive given how little work we had to do. If we were randomly trying to guess the label for each image, we would get an accuracy of about 10% so the algorithms performs considerably better than random. On the other hand, the previous applications of this library saw human-like performance for classifying different breeds of cats. So an accuracy of 53% does feel somewhat a bit disappointing. We can take a look at the results a bit more in detail by seeing the top misclassifications that took place:
interp = ClassificationInterpretation.from_learner(learn)
losses,idxs = interp.top_losses()
interp.plot_top_losses(9, figsize=(15,11))
A few problems become immediately apparent after looking at this. We can see them some images are just plain incorrect. For instance, the picture of tennis player Andy Murray on the second row shouldn’t be there since it doesn’t correspond to the right target label (in this case it is meant to be Rafael Nadal). The same can be seen for the second image in the first column where the tennis player Marin Cilic is shown and the tag label should be Kei Nishikori. Clearly, the dataset needs to be properly cleaned to avoid the use of incorrect images like this. Secondly, some images have the correct label but are too blurry to make out such as the bottom image in the second column. These should also be removed. Lastly, some of the predictions are just clearly incorrect. We can see that the algorithm a lot of the time predicts the class label to be Kevin Anderson with a high degree of certainty indicating that their might be a problem with images corresponding to this tennis player.
Next Steps
I reckon that there is a natural limit to using this approach for multi-class classification on celebrity datasets. Whereas a cat breed might be easy to distinguish due to some obvious features (fluffy/not fluffy, short hair/long hair), identifying people is more complex. Tennis players are photographed wearing different clothes, doing different gestures (executing a forehand or a backhand) and making different faces (sometimes they shout, sometimes they smile). Performing a multi-class classification on tennis players I think might lend itself naturally to a hierarchical approach whereby we first identify the different parts of the person’s body, and then concentrate on the face and perform classification on that.
In future posts, I’ll take a look at the state of the art in this field and see how to get an improvement on our accuracy metric (aside from not being lazy and cleaning the image dataset properly). Having said that, I think that 53% accuracy sets a good benchmark to try to beat.